






Azure Data Engineer Online Training
- 12k Enrolled Learners
- Weekend
- Live Class
(3450)
As we mentioned in our Hadoop Ecosystem blog, Apache Pig is an essential part of our Hadoop ecosystem. So, I would like to take you through this Apache Pig tutorial, which is a part of our Hadoop Tutorial Series. Learning it will help you understand and seamlessly execute the projects required for Big Data Hadoop Certification. In this Apache Pig Tutorial blog, I will talk about:
Before starting with the Apache Pig tutorial, I would like you to ask yourself a question – “while MapReduce was there for Big Data Analytics why Apache Pig came into picture?“
The sweet and simple answer to this is:
approximately 10 lines of Pig code is equal to 200 lines of MapReduce code.
Writing MapReduce jobs in Java is not an easy task for everyone. If you want a taste of MapReduce Java code, click here and you will understand the complexities. Thus, Apache Pig emerged as a boon for programmers who were not good with Java or Python. Even if someone who knows Java and is good with MapReduce, they will also prefer Apache Pig due to the ease working with Pig. Let us take a look now.
Programmers face difficulty writing MapReduce tasks as it requires Java or Python programming knowledge. For them, Apache Pig is a savior.
Now that we know why Apache Pig came into the picture, you would be curious to know what is Apache Pig? Let us move ahead in this Apache Pig tutorial blog and go through the introduction and features of Apache Pig.
Apache Pig is a platform, used to analyze large data sets representing them as data flows. It is designed to provide an abstraction over MapReduce, reducing the complexities of writing a MapReduce program. We can perform data manipulation operations very easily in Hadoop using Apache Pig.
The features of Apache pig are:
After knowing what is Apache Pig, now let us understand where we can use Apache Pig and what are the use cases which suits Apache Pig the most?
Apache Pig is used for analyzing and performing tasks involving ad-hoc processing. Apache Pig is used:
Now, in our Apache Pig Tutorial, let us go through the Twitter case study to better understand how Apache Pig helps in analyzing data and makes business understanding easier.
I will take you through a case study of Twitter where Twitter adopted Apache Pig.
Twitter’s data was growing at an accelerating rate (i.e. 10 TB data/day). Thus, Twitter decided to move the archived data to HDFS and adopt Hadoop for extracting the business values out of it.
Their major aim was to analyse data stored in Hadoop to come up with the following insights on a daily, weekly or monthly basis.
and many more…
So, for analyzing data, Twitter used MapReduce initially, which is parallel computing over HDFS (i.e. Hadoop Distributed File system).
For example, they wanted to analyse how many tweets are stored per user, in the given tweet table?
Using MapReduce, this problem will be solved sequentially as shown in the below image:
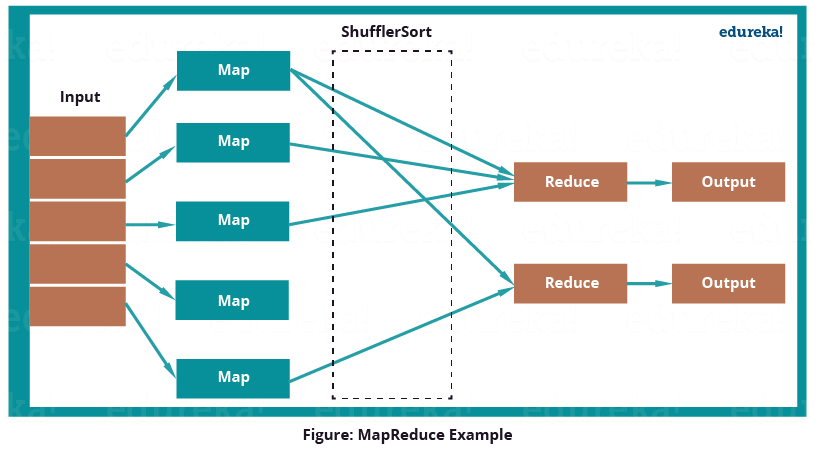
MapReduce program first inputs the key as rows and sends the tweet table information to mapper function. Then the Mapper function will select the user id and associate unit value (i.e. 1) to every user id. The Shuffle function will sort same user ids together. At last, Reduce function will add all the number of tweets together belonging to same user. The output will be user id, combined with user name and the number of tweets per user.
But while using MapReduce, they faced some limitations:
So, Twitter moved to Apache Pig for analysis. Now, joining data sets, grouping them, sorting them and retrieving data becomes easier and simpler. You can see in the below image how twitter used Apache Pig to analyse their large data set.

Twitter had both semi-structured data like Twitter Apache logs, Twitter search logs, Twitter MySQL query logs, application logs and structured data like tweets, users, block notifications, phones, favorites, saved searches, re-tweets, authentications, SMS usage, user followings, etc. which can be easily processed by Apache Pig.
Twitter dumps all its archived data on HDFS. It has two tables i.e. user data and tweets data. User data contains information about the users like username, followers, followings, number of tweets etc. While Tweet data contains tweet, its owner, number of re-tweets, number of likes etc. Now, twitter uses this data to analyse their customer’s behaviors and improve their past experiences.
We will see how Apache Pig solves the same problem which was solved by MapReduce:
Question: Analyzing how many tweets are stored per user, in the given tweet tables?
The below image shows the approach of Apache Pig to solve the problem:

The step by step solution of this problem is shown in the above image.
STEP 1– First of all, twitter imports the twitter tables (i.e. user table and tweet table) into the HDFS.
STEP 2– Then Apache Pig loads (LOAD) the tables into Apache Pig framework.
STEP 3– Then it joins and groups the tweet tables and user table using COGROUP command as shown in the above image.
This results in the inner Bag Data type, which we will discuss later in this blog.
Example of Inner bags produced (refer to the above image) –
(1,{(1,Jay,xyz),(1,Jay,pqr),(1,Jay,lmn)})
(2,{(2,Ellie,abc),(2,Ellie,vxy)})
(3, {(3,Sam,stu)})
STEP 4– Then the tweets are counted according to the users using COUNT command. So, that the total number of tweets per user can be easily calculated.
Example of tuple produced as (id, tweet count) (refer to the above image) –
(1, 3)
(2, 2)
(3, 1)
STEP 5– At last the result is joined with user table to extract the user name with produced result.
Example of tuple produced as (id, name, tweet count) (refer to the above image) –
(1, Jay, 3)
(2, Ellie, 2)
(3, Sam, 1)
STEP 6– Finally, this result is stored back in the HDFS.
Pig is not only limited to this operation. It can perform various other operations which I mentioned earlier in this use case.
These insights helps Twitter to perform sentiment analysis and develop machine learning algorithms based on the user behaviors and patterns.
You can check out this video where all the concepts related to Pig has been discussed.
For writing a Pig script, we need Pig Latin language and to execute them, we need an execution environment. The architecture of Apache Pig is shown in the below image.

Initially as illustrated in the above image, we submit Pig scripts to the Apache Pig execution environment which can be written in Pig Latin using built-in operators.
There are three ways to execute the Pig script:
From the above image you can see, after passing through Grunt or Pig Server, Pig Scripts are passed to the Parser. The Parser does type checking and checks the syntax of the script. The parser outputs a DAG (directed acyclic graph). DAG represents the Pig Latin statements and logical operators. The logical operators are represented as the nodes and the data flows are represented as edges.
Then the DAG is submitted to the optimizer. The Optimizer performs the optimization activities like split, merge, transform, and reorder operators etc. This optimizer provides the automatic optimization feature to Apache Pig. The optimizer basically aims to reduce the amount of data in the pipeline at any instance of time while processing the extracted data, and for that it performs functions like:
This is just a flavor of the optimization process. Over that it also performs Join, Order By and Group By functions.
To shutdown, automatic optimization, you can execute this command:
pig -optimizer_off [opt_rule | all ]After the optimization process, the compiler compiles the optimized code into a series of MapReduce jobs. The compiler is the one who is responsible for converting Pig jobs automatically into MapReduce jobs.
Finally, as shown in the figure, these MapReduce jobs are submitted for execution to the execution engine. Then the MapReduce jobs are executed and gives the required result. The result can be displayed on the screen using “DUMP” statement and can be stored in the HDFS using “STORE” statement.
After understanding the Architecture, now in this Apache Pig tutorial, I will explain you the Pig Latins’s Data Model.
The data model of Pig Latin enables Pig to handle all types of data. Pig Latin can handle both atomic data types like int, float, long, double etc. and complex data types like tuple, bag and map. I will explain them individually. The below image shows the data types and their corresponding classes using which we can implement them:

Atomic or scalar data types are the basic data types which are used in all the languages like string, int, float, long, double, char[], byte[]. These are also called the primitive data types. The value of each cell in a field (column) is an atomic data type as shown in the below image.
For fields, positional indexes are generated by the system automatically (also known as positional notation), which is represented by ‘$’ and it starts from $0, and grows $1, $2, so on… As compared with the below image $0 = S.No., $1 = Bands, $2 = Members, $3 = Origin.
Scalar data types are − ‘1’, ‘Linkin Park’, ‘7’, ‘California’ etc.

Now we will talk about complex data types in Pig Latin i.e. Tuple, Bag and Map.
Tuple is an ordered set of fields which may contain different data types for each field. You can understand it as the records stored in a row in a relational database. A Tuple is a set of cells from a single row as shown in the above image. The elements inside a tuple does not necessarily need to have a schema attached to it.
A tuple is represented by ‘()’ symbol.
Example of tuple − (1, Linkin Park, 7, California)
Since tuples are ordered, we can access fields in each tuple using indexes of the fields, like $1 form above tuple will return a value ‘Linkin Park’. You can notice that above tuple doesn’t have any schema attached to it.
A bag is a collection of a set of tuples and these tuples are subset of rows or entire rows of a table. A bag can contain duplicate tuples, and it is not mandatory that they need to be unique.
The bag has a flexible schema i.e. tuples within the bag can have different number of fields. A bag can also have tuples with different data types.
A bag is represented by ‘{}’ symbol.
Example of a bag − {(Linkin Park, 7, California), (Metallica, 8), (Mega Death, Los Angeles)}
But for Apache Pig to effectively process bags, the fields and their respective data types need to be in the same sequence.
Set of bags −
{(Linkin Park, 7, California), (Metallica, 8), (Mega Death, Los Angeles)},
{(Metallica, 8, Los Angeles), (Mega Death, 8), (Linkin Park, California)}
There are two types of Bag, i.e. Outer Bag or relations and Inner Bag.
Outer bag or relation is noting but a bag of tuples. Here relations are similar as relations in relational databases. To understand it better let us take an example:
{(Linkin Park, California), (Metallica, Los Angeles), (Mega Death, Los Angeles)}
This above bag explains the relation between the Band and their place of Origin.
On the other hand, an inner bag contains a bag inside a tuple. For Example, if we sort Band tuples based on Band’s Origin, we will get:
(Los Angeles, {(Metallica, Los Angeles), (Mega Death, Los Angeles)})
(California,{(Linkin Park, California)})
Here, first field type is a string while the second field type is a bag, which is an inner bag within a tuple.

A map is key-value pairs used to represent data elements. The key must be a chararray [] and should be unique like column name, so it can be indexed and value associated with it can be accessed on basis of the keys. The value can be of any data type.
Maps are represented by ‘[]’ symbol and key-value are separated by ‘#’ symbol, as you can see in the above image.
Example of maps− [band#Linkin Park, members#7 ], [band#Metallica, members#8 ]
Now as we learned Pig Latin’s Data Model. We will understand how Apache Pig handles schema as well as works with schema-less data.
Schema assigns name to the field and declares data type of the field. Schema is optional in Pig Latin but Pig encourage you to use them whenever possible, as the error checking becomes efficient while parsing the script which results in efficient execution of program. Schema can be declared as both simple and complex data types. During LOAD function, if the schema is declared it is also attached with the data.
Few Points on Schema in Pig:
I hope this Apache Pig tutorial blog is informative and you liked it. In this blog, you got to know the basics of Apache Pig, its data model and its architecture. The Twitter case study would have helped you to connect better. In my next blog of Hadoop Tutorial Series, we will be covering the installation of Apache Pig, so that you can get your hands dirty while working practically on Pig and executing Pig Latin commands.
Now that you have understood the Apache Pig Tutorial, check out the Hadoop training by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
Got a question for us? Please mention it in the comments section and we will get back to you.








































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










Hello Shubham Sinha, I have a doubt. I need your assistance to get it fixed. How to run multiple pig scripts in oozie using single job.properties file and single workflow.xml file.
Workflow.xml file :
${jobtracker}
${namenode}
mapred.job.queue.name
default mapred.compress.map.output
true
pig failed, error message[${wf:errorMessage(wf:errorMessage(wf:lastErrorNode())}]
INPUT1=${inputdir1}INPUT2=${inputdir2}OUTPUT1=${outputdir1}OUTPUT2=${outputdir2}
Job.properties file :
namenode=hdfs://localhost:8020
jobtracker=localhost:8032
inputdir1=/user/${user.name}/sourcefiles/yob/yobinput
inputdir2=/user/${user.name}/sourcefiles/employee/empinput
outputdir1=/user/${user.name}/SourceFiles/yob/yoboutput
outputdir1=/user/${user.name}/SourceFiles/employee/empoutput
queueName=default
oozie.use.system.libpath=true
oozie.wf.application.path=${namenode}/user/${user.name}/sourcefiles/scripts
PigScript:
%default TS `date +%Y-%m-%d-%H-%M-%S`
%default input1 /user/cloudera/sourcefiles/yob/yobinput
%default input2 /user/cloudera/sourcefiles/employee/empinput
%default output1 /user/cloudera/sourcefiles/yob/yoboutput
%default output2 /user/cloudera/sourcefiles/employee/empoutput
A = LOAD ‘$input1’ USING PigStorage(‘,’) as (name:chararray,gender:chararray,nooftimes:int);
B = FILTER A BY name ==’Smith’;
C = LOAD ‘$input2’ USING PigStorage(‘,’) as (empid:int,ename:chararray,job:chararray,mgr:int,hirdate:chararray,sal:int,comm:int,deptno:int);
D = FILTER C BY deptno == 20;
STORE B INTO ‘$output1/yob_$TS’ USING PigStorage(‘,’);
STORE D INTO ‘$output2/emp_$TS’ USING PigStorage(‘,’);
Hope this helps :)