






Azure Data Engineer Online Training
- 12k Enrolled Learners
- Weekend
- Live Class
(3450)
The never-ending surge for the Creation, Storage, Retrieval and Analysis of the colossal volumes of data, triggered the motivation behind the origin of Big Data Testing. Testing such a gigantic amount of data requires precision tools, remarkable frameworks and brilliant strategies.
Improve your understanding of the Big Data concepts and upgrade your job opportunities from the Big data hadoop course.
In this article, we will learn the Techniques, Tools, and Terminologies behind Big Data Testing.
Most of the users might end up with one question that asks “Why exactly we need Big Data Testing?” you might have written the queries correct and your Architecture might just be fine. Yet, there might be many possibilities for failure.
Let us assume a classic case of a drastic failure that occurred in a bank. The designers of the bank database name the Customer Bank location pin code column as CL, Customer ID column as CI and Customer Phone number column as CP.
 The bank wants to make the key-value pairs of Customer ID CI and Customer Phone number CP. In this scenario, the MapReduce Algorithm gets messed up between the letters P and L due to a typing error.
The bank wants to make the key-value pairs of Customer ID CI and Customer Phone number CP. In this scenario, the MapReduce Algorithm gets messed up between the letters P and L due to a typing error.

Then, the CP(Customer Phone Number) is replaced within the key-value pairs CL(Customer bank location Pin). Now the Customers wouldn’t get OTP and Phone Banking Facilities.

Just imagine this in a Real-Time situation. To avoid such mistakes, we prefer to test the Big-Data. Learn more about Big Data concepts from the Azure Data Engineer Certification Course.

Big Data Testing can be defined as the procedure that involves examining and validating the functionality of the Big Data Applications. Big Data is a collection of a huge amount of data that traditional storage systems cannot handle.
Testing such a huge amount of data would take some special tools, techniques, and terminologies which will be discussed in the later sections of this article.
Testing an Application that handles terabytes of data would take the skill from a whole new level and out of the box thinking. The core and important tests that the Quality Assurance Team concentrates is based on three Scenarios. Namely,

Batch Data Processing Test
The Batch Data Processing Test involves test procedures that run the data when the applications in Batch Processing mode where the application is processed using Batch Processing Storage units like HDFS. The Batch Process Testing mainly involves
Real-Time Data Processing Test
The Real-Time Data Processing Test deals with the data when the application is in Real-Time Data Processing mode. The application is run using Real-Time Processing tools like Spark.
Real-Time testing involves the application to be tested in the real-time environment and it is checked for its stability.
Interactive Data Processing Test
The Interactive Data Processing Test integrates the real-life test protocols that interact with the application as in the view of the real-life user. Interactive Data Processing mode uses Interactive Processing tools like HiveSQL. Learn more about Big Data concepts from the Azure Data Engineering Training in Mumbai.

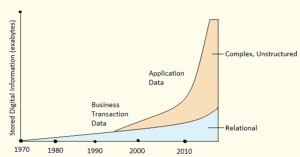
Big-Data gains its fame through its superiority in handling multiple formats of data which the traditional data processing units fail to handle. The data formats which the big data can handle are as follows.
Structured Data
Any tabular data which is meaningfully organised under rows and columns with easy accessibility is known as Structured Data. It can be organised under named columns in different storage units such as an RDBMS.
Example: Tabular Data
Semi-Structured Data
Semi-Structured Data lies perfectly in between the Structured and Unstructured Data. It cannot be directly ingested into an RDBMS as it includes metadata, tags, and sometimes duplicate values. Data needs some operations to be applied to it before the data is ready to be ingested.
Example: .CSV, .JSON
Unstructured Data
Data that does not obey any kind structure is known as Unstructured data. Unlike the Structured Data, The unstructured Data is difficult to store and retrieve. Most of the data generated by the organisations are Unstructured type of data.
Example: Images, Videos, Audio
Unleash the power of distributed computing and scalable data processing with our Apache Spark Certification.

Owning the perfect Environment for testing a Big Data Application is very crucial. The basic requirements that makeup Data Testing are as follows.
Get a further understanding of the Big Data technologies and applications from the Hadoop training in Mumbai.
The General approach to test a Big Data Application involves the following stages.

Data Ingestion
Data is first loaded from source to Big Data System using extracting tools. The Storage might be HDFS, MongoDB or any similar storage. Then, the loaded data is cross-checked for errors and missing values.
Example: Talend
Data Processing
In this stage, the key-value pairs for the data get generated. Later, the MapReduce logic is applied to all the nodes and checked if the algorithm works fine or not. A data validation process takes place here to make sure the output is generated as expected.
Validation of the Output
At this stage, the output generated is ready to be migrated to the data warehouse. Here, The transformation logic is checked, the data integrity is verified and the key-value pairs at the location are validated for accuracy.
There are many categories involved in which a Big Data Application can be tested. Few of the major categories are enlisted below.
Unit Testing
Unit Testing in Big Data is similar to any other unit testing in simpler applications. The complete Big Data Application is divided into segments and each segment is rigorously tested with multiple possibilities for an expected outcome. If the segment fails, then it is sent back to the developments and improvements.
Functional Testing
Functional Testing can be otherwise called as the different phases in testing the big data application. The Big Data Application is designed to deal with huge blocks of data. Such a huge volume and variety of data is often prone to bring data issues, such as bad data, duplicate values, metadata, missing values and whatnot.
This is exactly why the pioneers in testing the big data, designed the procedure for functional testing of big data. The different phases in which the big data is tested are as follows.
Now, let us discuss each one of these phases in an elaborate way.
Data Validation Phase
Data Integrity Phase
Data Ingestion Phase
Data Processing Phase
Data Storage Phase
Report Generation Phase
Non-Functional Testing
The Non-Functional Testing phase takes care of the three major dimensions and characteristics of Big Data. The Volume, Velocity, and finally the Variety of the Big Data. There are five stages involved in Non-Functional Testing.
Data Quality Monitoring
Infrastructure
Data Security
Data Performance
Fail-over Test Mechanism
Performance Testing
Performance testing highly concentrates on the performance delivered by all the components of the big data system. Performance testing includes the following Categories.

Data Collecting Phase
In this Stage, Big Data System is validated based on its speed and capacity to grasp the data within a given timeframe from the different sources like RDBMS, Databases, Data-ware houses and many more.
Data Ingesting Phase
The next phase after Data Collection is the Data Ingestion. Here the application is tested and validated based on its pace and capacity to load the collected data from the source to the destination which might be HDFS, MongoDB, Cassandra or any similar Data Storage unit.
Data Processing
Here, the Application is tested based on the Map-Reduce logic written. The logic is run against every single node in the cluster and the processing speeds are validated. The Queries to be executed are expected to perform with high speeds with low latency.
Component Peripheral testing
This stage is related to component performance. Each component in the system should be highly available and connected. The component backup should be online when any node faces failure. High Capacity Data Exchange should smoothly be supported.
Performance Testing Approach

Parameters involved in Performance testing
Architecture Testing
Architecture testing concentrates on establishing a stable Hadoop Architecture. The architecture of Big Data Processing Application plays a key role in achieving smooth operations. Poorly designed architecture leads to chaos like,
Various tools used in testing the Big Data are mentioned as shown below:
| Process | Tools Description |
| Data Ingestion | Zookeeper, Kafka, Sqoop |
| Data Processing | MapR, Hive, Pig |
| Data Storage | Amazon S3, HDFS |
| Data Migration | Talend, Kettle, CloverDX |
You can check Big Data Masters Online course to learn more about Big Data from basic to advance level.
| Traditional Testing | Big Data Testing |
| Supports Structured Data | Supports all types of Data |
| Testing Does not R&D | R&D is Testing needed |
| limited Data size does not require special Environment | Special Environment is needed because of the huge data |
| Uses EXCEL based Macros or UI based automation tools | Has a vast range of programmable tools for testing |
| Basic Operations knowledge is enough to run tests | The highly qualified skill set is necessary |
With this, we come to an end of this article. I hope I have thrown some light on to your knowledge on Big Data and its Technologies.
Now that you have understood Big data and its Technologies, check out the Hadoop training in Bangalore by Edureka, a trusted online learning company with a network of more than 250,000 satisfied learners spread across the globe. The Edureka Big Data Hadoop Certification Training course helps learners become expert in HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume and Sqoop using real-time use cases on Retail, Social Media, Aviation, Tourism, Finance domain.
If you have any query related to this article, then please write to us in the comment section below and we will respond to you as early as possible.




































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP









