






Azure Data Engineer Online Training
- 12k Enrolled Learners
- Weekend
- Live Class
(3450)


Apache Spark is a lightning-fast cluster computing framework designed for fast computation. With the advent of real-time processing frameworks in the Big Data Ecosystem, companies are using Apache Spark rigorously in their solutions. Spark SQL is a new module in Spark which integrates relational processing with Spark’s functional programming API. It supports querying data either via SQL or via the Hive Query Language. Through this blog, I will introduce you to this new exciting domain of Spark SQL.
The following provides the storyline for the blog:
Spark SQL integrates relational processing with Spark’s functional programming. It provides support for various data sources and makes it possible to weave SQL queries with code transformations thus resulting in a very powerful tool.
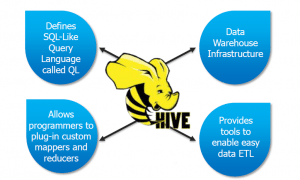
Spark SQL originated as Apache Hive to run on top of Spark and is now integrated with the Spark stack. Apache Hive had certain limitations as mentioned below. Spark SQL was built to overcome these drawbacks and replace Apache Hive.
Spark SQL is faster than Hive when it comes to processing speed. Below I have listed down a few limitations of Hive over Spark SQL.
These drawbacks gave way to the birth of Spark SQL. But the question which still pertains in most of our minds is,
Spark SQL is not a database but a module that is used for structured data processing. It majorly works on DataFrames which are the programming abstraction and usually act as a distributed SQL query engine.
Let us explore, what Spark SQL has to offer. Spark SQL blurs the line between RDD and relational table. It offers much tighter integration between relational and procedural processing through declarative DataFrame APIs which integrates with Spark code. It also provides higher optimization. DataFrame API and Datasets API are the ways to interact How does Spark SQL work with Spark SQL?
With Spark SQL, Apache Spark is accessible to more users and improves optimization for the current ones. Spark SQL provides DataFrame APIs which perform relational operations on both external data sources and Spark’s built-in distributed collections. It introduces an extensible optimizer called Catalyst as it helps in supporting a wide range of data sources and algorithms in Big-data.
Spark runs on both Windows and UNIX-like systems (e.g. Linux, Microsoft, Mac OS). It is easy to run locally on one machine — all you need is to have java installed on your system PATH, or the JAVA_HOME environment variable pointing to a Java installation.
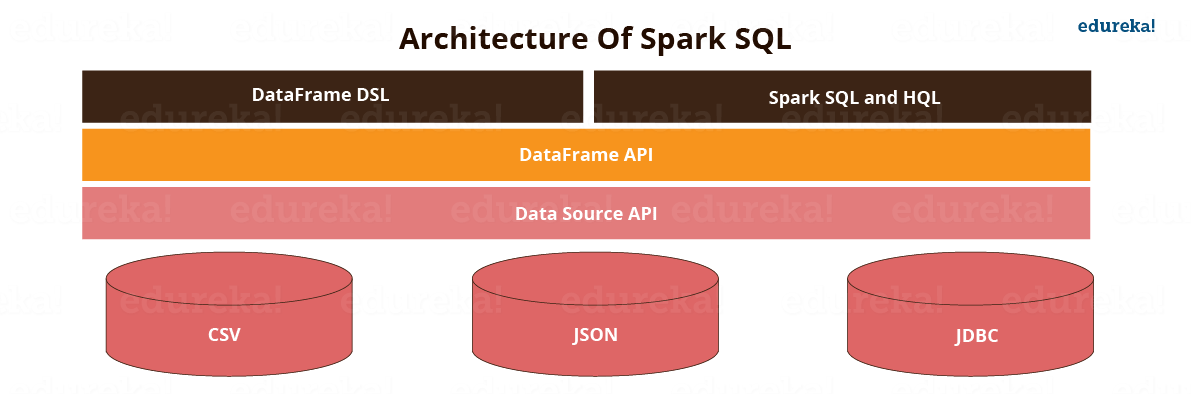
Figure: Architecture of Spark SQL.
Spark SQL has the following four libraries which are used to interact with relational and procedural processing:
This is a universal API for loading and storing structured data.
A DataFrame is a distributed collection of data organized into named columns. It is equivalent to a relational table in SQL used for storing data into tables.
SQL Interpreter and Optimizer is based on functional programming constructed in Scala.
e.g. Catalyst is a modular library that is made as a rule-based system. Each rule in the framework focuses on distinct optimization.
SQL Service is the entry point for working along with structured data in Spark. It allows the creation of DataFrame objects as well as the execution of SQL queries.
The following are the features of Spark SQL:
Spark SQL queries are integrated with Spark programs. Spark SQL allows us to query structured data inside Spark programs, using SQL or a DataFrame API which can be used in Java, Scala, Python and R. To run the streaming computation, developers simply write a batch computation against the DataFrame / Dataset API, and Spark automatically increments the computation to run it in a streaming fashion. This powerful design means that developers don’t have to manually manage state, failures, or keep the application in sync with batch jobs. Instead, the streaming job always gives the same answer as a batch job on the same data.
DataFrames and SQL support a common way to access a variety of data sources, like Hive, Avro, Parquet, ORC, JSON, and JDBC. This joins the data across these sources. This is very helpful to accommodate all the existing users into Spark SQL.
Spark SQL runs unmodified Hive queries on current data. It rewrites the Hive front-end and meta store, allowing full compatibility with current Hive data, queries, and UDFs.
The connection is through JDBC or ODBC. JDBC and ODBC are the industry norms for connectivity for business intelligence tools.
Spark SQL incorporates a cost-based optimizer, code generation, and columnar storage to make queries agile alongside computing thousands of nodes using the Spark engine, which provides full mid-query fault tolerance. The interfaces provided by Spark SQL provide Spark with more information about the structure of both the data and the computation being performed. Internally, Spark SQL uses this extra information to perform extra optimization. Spark SQL can directly read from multiple sources (files, HDFS, JSON/Parquet files, existing RDDs, Hive, etc.). It ensures the fast execution of existing Hive queries.
The image below depicts the performance of Spark SQL when compared to Hadoop. Spark SQL executes up to 100x times faster than Hadoop.
 Figure:Runtime of Spark SQL vs Hadoop. Spark SQL is faster
Figure:Runtime of Spark SQL vs Hadoop. Spark SQL is faster
Source:Cloudera Apache Spark Blog
The example below defines a UDF to convert a given text to upper case.
Code explanation:
1. Creating a dataset “hello world”
2. Defining a function ‘upper’ which converts a string into upper case.
3. We now import the ‘udf’ package into Spark.
4. Defining our UDF, ‘upperUDF’ and importing our function ‘upper’.
5. Displaying the results of our User Defined Function in a new column ‘upper’.
val dataset = Seq((0, "hello"),(1, "world")).toDF("id","text")
val upper: String => String =_.toUpperCase
import org.apache.spark.sql.functions.udf
val upperUDF = udf(upper)
dataset.withColumn("upper", upperUDF('text)).show
 Figure: Demonstration of a User Defined Function, upperUDF
Figure: Demonstration of a User Defined Function, upperUDF
Code explanation:
1. We now register our function as ‘myUpper’
2. Cataloging our UDF among the other functions.
spark.udf.register("myUpper", (input:String) => input.toUpperCase)
spark.catalog.listFunctions.filter('name like "%upper%").show(false)
 Figure: Results of the User Defined Function, upperUDF
Figure: Results of the User Defined Function, upperUDF
We will now start querying using Spark SQL. Note that the actual SQL queries are similar to the ones used in popular SQL clients.
Starting the Spark Shell. Go to the Spark directory and execute ./bin/spark-shell in the terminal to being the Spark Shell.
For the querying examples shown in the blog, we will be using two files, ’employee.txt’ and ’employee.json’. The images below show the content of both the files. Both these files are stored at ‘examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala’ inside the folder containing the Spark installation (~/Downloads/spark-2.0.2-bin-hadoop2.7). So, all of you who are executing the queries, place them in this directory or set the path to your files in the lines of code below.

Figure: Contents of employee.txt
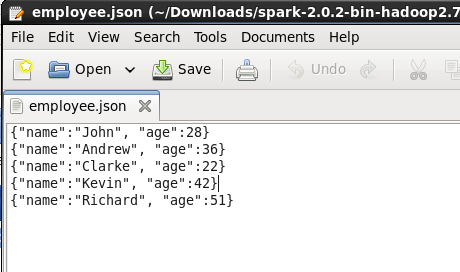
Figure: Contents of employee.json
Code explanation:
1. We first import a Spark Session into Apache Spark.
2. Creating a Spark Session ‘spark’ using the ‘builder()’ function.
3. Importing the Implicts class into our ‘spark’ Session.
4. We now create a DataFrame ‘df’ and import data from the ’employee.json’ file.
5. Displaying the DataFrame ‘df’. The result is a table of 5 rows of ages and names from our ’employee.json’ file.
import org.apache.spark.sql.SparkSession
val spark = SparkSession.builder().appName("Spark SQL basic example").config("spark.some.config.option", "some-value").getOrCreate()
import spark.implicits._
val df = spark.read.json("examples/src/main/resources/employee.json")
df.show()
 Figure: Starting a Spark Session and displaying DataFrame of employee.json
Figure: Starting a Spark Session and displaying DataFrame of employee.json
Code explanation:
1. Importing the Implicts class into our ‘spark’ Session.
2. Printing the schema of our ‘df’ DataFrame.
3. Displaying the names of all our records from ‘df’ DataFrame.
import spark.implicits._
df.printSchema()
df.select("name").show()
 Figure: Schema of a DataFrame
Figure: Schema of a DataFrame
Code explanation:
1. Displaying the DataFrame after incrementing everyone’s age by two years.
2. We filter all the employees above age 30 and display the result.
df.select($"name", $"age" + 2).show() df.filter($"age" > 30).show()
 Figure: Basic SQL operations on employee.json
Figure: Basic SQL operations on employee.json
Code explanation:
1. Counting the number of people with the same ages. We use the ‘groupBy’ function for the same.
2. Creating a temporary view ’employee’ of our ‘df’ DataFrame.
3. Perform a ‘select’ operation on our ’employee’ view to display the table into ‘sqlDF’.
4. Displaying the results of ‘sqlDF’.
df.groupBy("age").count().show()
df.createOrReplaceTempView("employee")
val sqlDF = spark.sql("SELECT * FROM employee")
sqlDF.show()
 Figure: SQL operations on employee.json
Figure: SQL operations on employee.json
After understanding DataFrames, let us now move on to Dataset API. The below code creates a Dataset class in SparkSQL.
Code explanation:
1. Creating a class ‘Employee’ to store name and age of an employee.
2. Assigning a Dataset ‘caseClassDS’ to store the record of Andrew.
3. Displaying the Dataset ‘caseClassDS’.
4. Creating a primitive Dataset to demonstrate mapping of DataFrames into Datasets.
5. Assigning the above sequence into an array.
case class Employee(name: String, age: Long)
val caseClassDS = Seq(Employee("Andrew", 55)).toDS()
caseClassDS.show()
val primitiveDS = Seq(1, 2, 3).toDS
()primitiveDS.map(_ + 1).collect()
 Figure: Creating a Dataset
Figure: Creating a Dataset
Code explanation:
1. Setting the path to our JSON file ’employee.json’.
2. Creating a Dataset and from the file.
3. Displaying the contents of ’employeeDS’ Dataset.
val path = "examples/src/main/resources/employee.json" val employeeDS = spark.read.json(path).as[Employee] employeeDS.show()
 Figure: Creating a Dataset from a JSON file
Figure: Creating a Dataset from a JSON file
Spark introduces the concept of an RDD (Resilient Distributed Dataset), an immutable fault-tolerant, distributed collection of objects that can be operated on in parallel. An RDD can contain any type of object and is created by loading an external dataset or distributing a collection from the driver program.
Schema RDD is a RDD where you can run SQL on. It is more than SQL. It is a unified interface for structured data.
Code explanation:
1. Importing Expression Encoder for RDDs. RDDs are similar to Datasets but use encoders for serialization.
2. Importing Encoder library into the shell.
3. Importing the Implicts class into our ‘spark’ Session.
4. Creating an ’employeeDF’ DataFrame from ’employee.txt’ and mapping the columns based on the delimiter comma ‘,’ into a temporary view ’employee’.
5. Creating the temporary view ’employee’.
6. Defining a DataFrame ‘youngstersDF’ which will contain all the employees between the ages of 18 and 30.
7. Mapping the names from the RDD into ‘youngstersDF’ to display the names of youngsters.
import org.apache.spark.sql.catalyst.encoders.ExpressionEncoder
import org.apache.spark.sql.Encoder
import spark.implicits._
val employeeDF = spark.sparkContext.textFile("examples/src/main/resources/employee.txt").map(_.split(",")).map(attributes => Employee(attributes(0), attributes(1).trim.toInt)).toDF()
employeeDF.createOrReplaceTempView("employee")
val youngstersDF = spark.sql("SELECT name, age FROM employee WHERE age BETWEEN 18 AND 30")
youngstersDF.map(youngster => "Name: " + youngster(0)).show()
 Figure: Creating a DataFrame for transformations
Figure: Creating a DataFrame for transformations
Code explanation:
1. Converting the mapped names into string for transformations.
2. Using the mapEncoder from Implicits class to map the names to the ages.
3. Mapping the names to the ages of our ‘youngstersDF’ DataFrame. The result is an array with names mapped to their respective ages.
youngstersDF.map(youngster => "Name: " + youngster.getAs[String]("name")).show()
implicit val mapEncoder = org.apache.spark.sql.Encoders.kryo[Map[String, Any]]
youngstersDF.map(youngster => youngster.getValuesMap[Any](List("name", "age"))).collect()
 Figure: Mapping using DataFrames
Figure: Mapping using DataFrames
RDDs support two types of operations:
Transformations in Spark are “lazy”, meaning that they do not compute their results right away. Instead, they just “remember” the operation to be performed and the dataset (e.g., file) to which the operation is to be performed. The transformations are computed only when an action is called and the result is returned to the driver program and stored as Directed Acyclic Graphs (DAG). This design enables Spark to run more efficiently. For example, if a big file was transformed in various ways and passed to first action, Spark would only process and return the result for the first line, rather than do the work for the entire file.
 Figure: Ecosystem of Schema RDD in Spark SQL
Figure: Ecosystem of Schema RDD in Spark SQL
By default, each transformed RDD may be recomputed each time you run an action on it. However, you may also persist an RDD in memory using the persist or cache method, in which case Spark will keep the elements around on the cluster for much faster access the next time you query it.
Resilient Distributed Datasets (RDDs) are distributed memory abstraction which lets programmers perform in-memory computations on large clusters in a fault tolerant manner. RDDs can be created from any data source. Eg: Scala collection, local file system, Hadoop, Amazon S3, HBase Table, etc.
Code explanation:
1. Importing the ‘types’ class into the Spark Shell.
2. Importing ‘Row’ class into the Spark Shell. Row is used in mapping RDD Schema.
3. Creating a RDD ’employeeRDD’ from the text file ’employee.txt’.
4. Defining the schema as “name age”. This is used to map the columns of the RDD.
5. Defining ‘fields’ RDD which will be the output after mapping the ’employeeRDD’ to the schema ‘schemaString’.
6. Obtaining the type of ‘fields’ RDD into ‘schema’.
import org.apache.spark.sql.types._
import org.apache.spark.sql.Row
val employeeRDD = spark.sparkContext.textFile("examples/src/main/resources/employee.txt")
val schemaString = "name age"
val fields = schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, nullable = true))
val schema = StructType(fields)
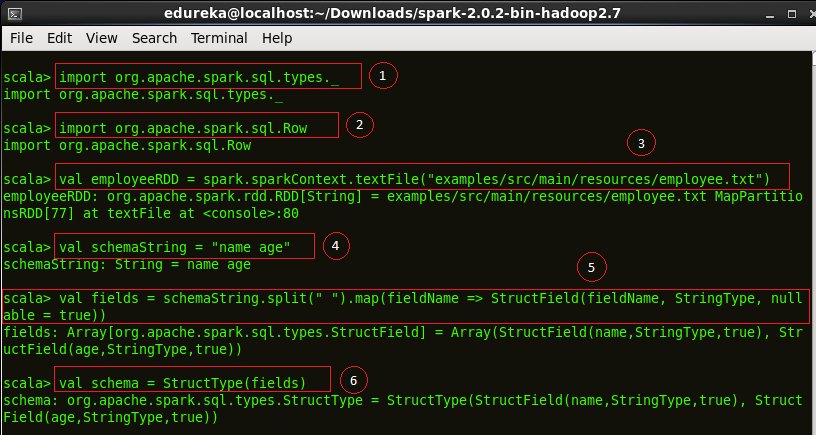 Figure: Specifying Schema for RDD transformation
Figure: Specifying Schema for RDD transformation
Code explanation:
1. We now create a RDD called ‘rowRDD’ and transform the ’employeeRDD’ using the ‘map’ function into ‘rowRDD’.
2. We define a DataFrame ’employeeDF’ and store the RDD schema into it.
3. Creating a temporary view of ’employeeDF’ into ’employee’.
4. Performing the SQL operation on ’employee’ to display the contents of employee.
5. Displaying the names of the previous operation from the ’employee’ view.
val rowRDD = employeeRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim))
val employeeDF = spark.createDataFrame(rowRDD, schema)
employeeDF.createOrReplaceTempView("employee")
val results = spark.sql("SELECT name FROM employee")
results.map(attributes => "Name: " + attributes(0)).show()
 Figure: Result of RDD transformation
Figure: Result of RDD transformation
Even though RDDs are defined, they don’t contain any data. The computation to create the data in a RDD is only done when the data is referenced. e.g. Caching results or writing out the RDD.
Spark SQL caches tables using an in-memory columnar format:
The below code will read employee.json file and create a DataFrame. We will then use it to create a Parquet file.
Code explanation:
1. Importing Implicits class into the shell.
2. Creating an ’employeeDF’ DataFrame from our ’employee.json’ file.
import spark.implicits._
val employeeDF = spark.read.json("examples/src/main/resources/employee.json")
 Figure: Loading a JSON file into DataFrame
Figure: Loading a JSON file into DataFrame
Code explanation:
1. Creating a ‘parquetFile’ temporary view of our DataFrame.
2. Selecting the names of people between the ages of 18 and 30 from our Parquet file.
3. Displaying the result of the Spark SQL operation.
employeeDF.write.parquet("employee.parquet")
val parquetFileDF = spark.read.parquet("employee.parquet")
parquetFileDF.createOrReplaceTempView("parquetFile")
val namesDF = spark.sql("SELECT name FROM parquetFile WHERE age BETWEEN 18 AND 30")
namesDF.map(attributes => "Name: " + attributes(0)).show()
 Figure: Displaying results from a Parquet DataFrame
Figure: Displaying results from a Parquet DataFrame
We will now work on JSON data. As Spark SQL supports JSON dataset, we create a DataFrame of employee.json. The schema of this DataFrame can be seen below. We then define a Youngster DataFrame and add all the employees between the ages of 18 and 30.
Code explanation:
1. Setting to path to our ’employee.json’ file.
2. Creating a DataFrame ’employeeDF’ from our JSON file.
3. Printing the schema of ’employeeDF’.
4. Creating a temporary view of the DataFrame into ’employee’.
5. Defining a DataFrame ‘youngsterNamesDF’ which stores the names of all the employees between the ages of 18 and 30 present in ’employee’.
6. Displaying the contents of our DataFrame.
val path = "examples/src/main/resources/employee.json"
val employeeDF = spark.read.json(path)
employeeDF.printSchema()
employeeDF.createOrReplaceTempView("employee")
val youngsterNamesDF = spark.sql("SELECT name FROM employee WHERE age BETWEEN 18 AND 30")
youngsterNamesDF.show()
 Figure: Operations on JSON Datasets
Figure: Operations on JSON Datasets
Code explanation:
1. Creating a RDD ‘otherEmployeeRDD’ which will store the content of employee George from New Delhi, Delhi.
2. Assigning the contents of ‘otherEmployeeRDD’ into ‘otherEmployee’.
3. Displaying the contents of ‘otherEmployee’.
val otherEmployeeRDD = spark.sparkContext.makeRDD("""{"name":"George","address":{"city":"New Delhi","state":"Delhi"}}""" :: Nil)
val otherEmployee = spark.read.json(otherEmployeeRDD)
otherEmployee.show()
 Figure: RDD transformations on JSON Dataset
Figure: RDD transformations on JSON Dataset
We perform a Spark example using Hive tables.
Code explanation:
1. Importing ‘Row’ class into the Spark Shell. Row is used in mapping RDD Schema.
2. Importing Spark Session into the shell.
3. Creating a class ‘Record’ with attributes Int and String.
4. Setting the location of ‘warehouseLocation’ to Spark warehouse.
5. We now build a Spark Session ‘spark’ to demonstrate Hive example in Spark SQL.
6. Importing Implicits class into the shell.
7. Importing SQL library into the Spark Shell.
8. Creating a table ‘src’ with columns to store key and value.
import org.apache.spark.sql.Row
import org.apache.spark.sql.SparkSession
case class Record(key: Int, value: String)
val warehouseLocation = "spark-warehouse"
val spark = SparkSession.builder().appName("Spark Hive Example").config("spark.sql.warehouse.dir", warehouseLocation).enableHiveSupport().getOrCreate()
import spark.implicits._
import spark.sql
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
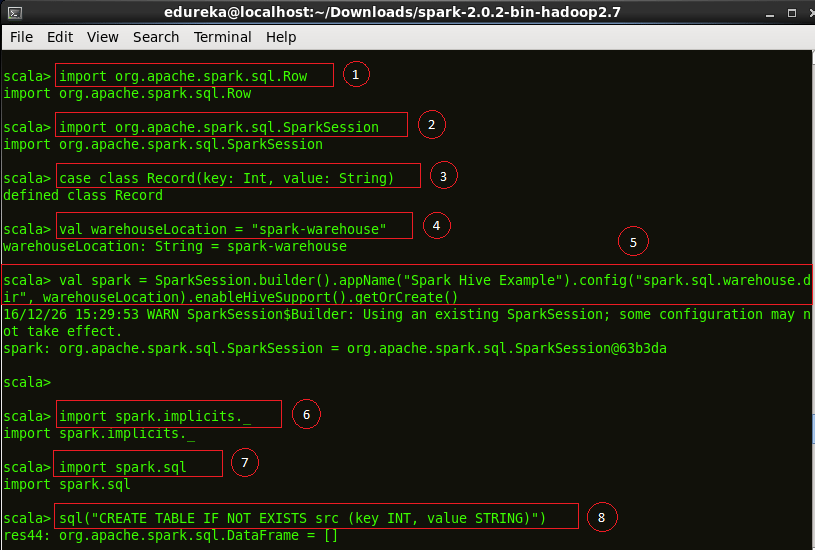 Figure: Building a Session for Hive
Figure: Building a Session for Hive
Code explanation:
1. We now load the data from the examples present in Spark directory into our table ‘src’.
2. The contents of ‘src’ is displayed below.
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
sql("SELECT * FROM src").show()
 Figure: Selection using Hive tables
Figure: Selection using Hive tables
Code explanation:
1. We perform the ‘count’ operation to select the number of keys in ‘src’ table.
2. We now select all the records with ‘key’ value less than 10 and store it in the ‘sqlDF’ DataFrame.
3. Creating a Dataset ‘stringDS’ from ‘sqlDF’.
4. Displaying the contents of ‘stringDS’ Dataset.
sql("SELECT COUNT(*) FROM src").show()
val sqlDF = sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key") val stringsDS = sqlDF.map {case Row(key: Int, value: String) => s"Key: $key, Value: $value"}
stringsDS.show()

Figure: Creating DataFrames from Hive tables
Code explanation:
1. We create a DataFrame ‘recordsDF’ and store all the records with key values 1 to 100.
2. Create a temporary view ‘records’ of ‘recordsDF’ DataFrame.
3. Displaying the contents of the join of tables ‘records’ and ‘src’ with ‘key’ as the primary key.
val recordsDF = spark.createDataFrame((1 to 100).map(i => Record(i, s"val_$i")))
recordsDF.createOrReplaceTempView("records")
sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show()
 Figure: Recording the results of Hive operations
Figure: Recording the results of Hive operations
So this concludes our blog. I hope you enjoyed reading this blog and found it informative. By now, you must have acquired a sound understanding of what Spark SQL is. The hands-on examples will give you the required confidence to work on any future projects you encounter in Spark SQL. Practice is the key to mastering any subject and I hope this blog has created enough interest in you to explore learning further on Spark SQL.
Got a question for us? Please mention it in the comments section and we will get back to you at the earliest.
If you wish to learn Spark and build a career in domain of Spark and build expertise to perform large-scale Data Processing using RDD, Spark Streaming, SparkSQL, MLlib, GraphX and Scala with Real Life use-cases, check out our interactive, live-online Apache Spark Certification Training here, that comes with 24*7 support to guide you throughout your learning period.





































 REGISTER FOR FREE WEBINAR
REGISTER FOR FREE WEBINAR  Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP
Thank you for registering Join Edureka Meetup community for 100+ Free Webinars each month JOIN MEETUP GROUP










how does subquery works in spark sql?
For example:How to get max salary from employee table in each dept with emp name?